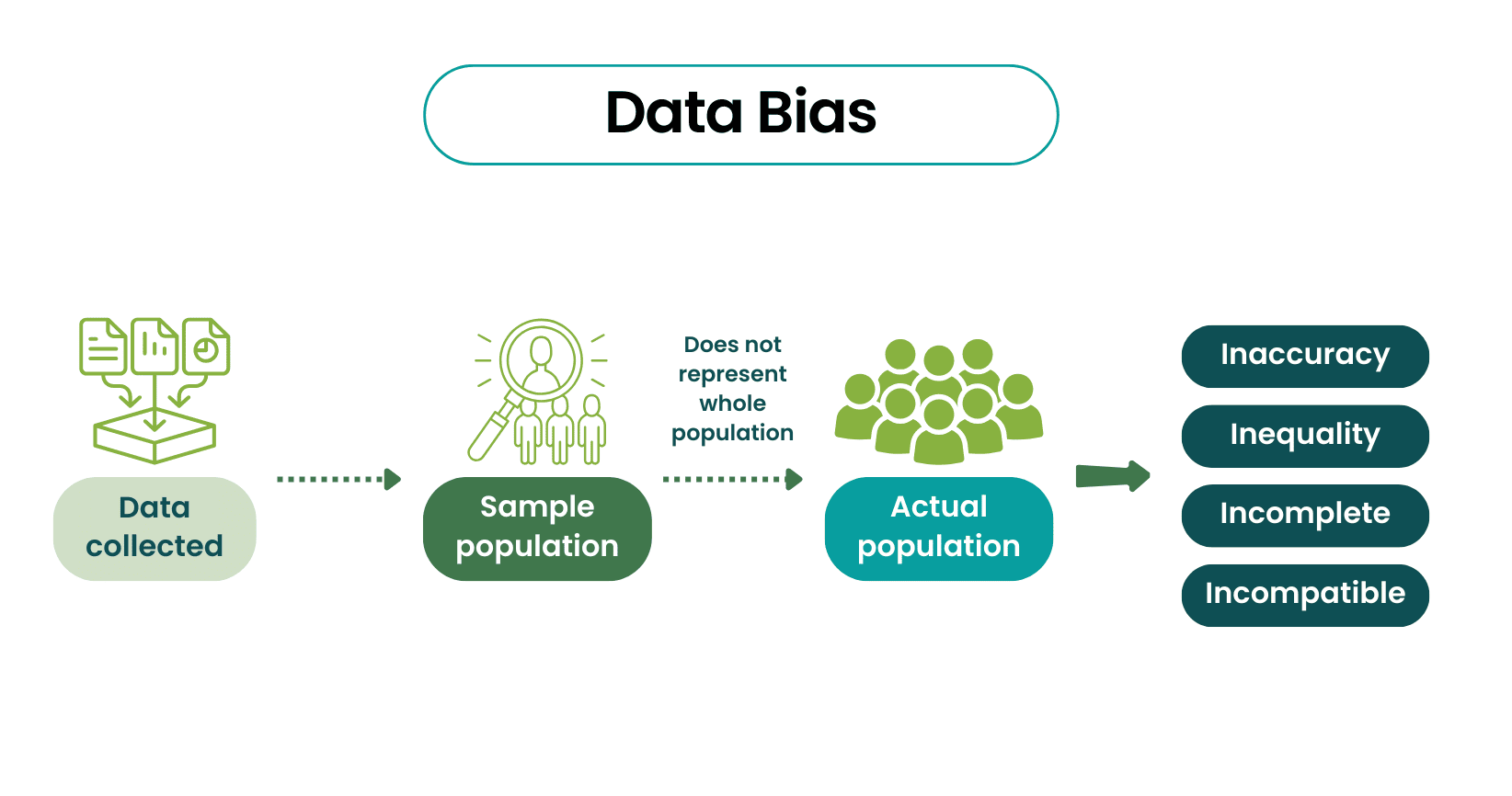
Research bias is often introduced as a technical nuisance. Something to be “adjusted for,” “controlled,” or acknowledged briefly in the limitations section. In practice, bias enters much earlier—long before any statistical model is chosen.
Bias begins the moment we decide:
- who counts as a participant
- which data sources are acceptable
- what gets recorded consistently, and what does not
- which explanations feel plausible enough to consider
By the time analysis starts, most of the damage—if there is any—has already been done.
Why bias survives good intentions
Most researchers are not careless. They follow protocols, apply inclusion criteria, and cite standard definitions of bias. Yet biased studies persist. This is because bias is not primarily a failure of technique. It is a failure of imagination.
Bias thrives when researchers fail to imagine how reality deviates from the clean structure assumed by the study. Patients do not arrive randomly. Records are not missing at random. Measurements are not taken under uniform conditions.
We know this in theory. But knowing it abstractly is very different from building it into the workflow.
A bias I didn’t see: referral patterns
In my ARM imaging study, I initially assumed that patients arriving at our tertiary center represented the full spectrum of anorectal malformations.
They didn’t.
District hospitals managed straightforward cases locally and referred complex cases—high malformations, unclear anatomy—to us. Before I enrolled a single patient, my dataset was already enriched with difficult cases.
This had consequences:
- Imaging predictors were tested almost exclusively on complex anatomy
- Sensitivity appeared artificially high
- Generalizability was limited to tertiary referral settings
I only recognized this when a reviewer asked: “Why are 80% of your cases high malformations when population studies show a near 50–50 distribution?”
The bias wasn’t in my measurements or analysis. It was in the structure of patient flow, long before data collection began.
Bias enters through structure, not mistakes
Bias is often associated with error—sloppy data entry, careless measurement, flawed analysis.
More often, it is structural. It comes from:
- referral systems that shape who appears in your dataset
- clinical workflows that determine which data are collected
- institutional practices that influence documentation
These forces operate even when everyone involved is competent and well-intentioned.
This is why bias cannot be fully “fixed” downstream. It must be anticipated upstream.
Documentation bias: when missingness is meaningful
Another bias I underestimated was documentation.
Complications were documented meticulously—multiple notes, lab values, follow-up visits. Routine recoveries, by contrast, were summarized in a single line: “Uneventful recovery. Discharged on POD 3.”
When I analyzed outcomes:
- Complications were richly described
- Smooth recoveries were sparsely documented
Missing data was not random. It was informative.
This made associations involving complications easier to detect, while uncomplicated outcomes appeared deceptively simple and homogeneous.
Again, no one made a mistake. The bias emerged from what clinicians naturally pay attention to—and write down.
Seeing bias early changes what you can claim
Researchers who think seriously about bias early tend to make different design decisions. They ask:
- Who never makes it into this dataset?
- Who is overrepresented, and why?
- What information is more likely to be missing—and from whom?
These questions do not eliminate bias. But they clarify which claims remain defensible.
For my study, this meant accepting a narrower conclusion:
Not: “Ultrasound accurately predicts surgical complexity in all ARM cases.”
But: “Ultrasound correlates with surgical approach in tertiary referral populations with moderate-to-complex malformations.”
The second claim is less ambitious—but honest.
Knowing when not to adjust
Once bias is recognized, there is often pressure to correct it statistically. Adjustments can help. Sensitivity analyses can help. But they cannot transform a fundamentally limited dataset into something it is not.
At one point, I considered multiple statistical corrections for referral bias. My supervisor stopped me:
“You’re trying to statistically create the dataset you wish you had.”
He was right.
Instead of overcorrecting, I focused on:
- Describing the selection process clearly
- Limiting claims to the population actually studied
- Discussing implications for generalizability
- Proposing better designs for future work
Reviewers responded positively—not because the bias disappeared, but because it was acknowledged without overreach.
Using AI to surface hidden assumptions
I sometimes use AI not to analyze data, but to challenge assumptions about it. A simple prompt:
My study examines [topic] using [data source].
Patients are enrolled from [setting].
What systematic biases might affect who appears in this dataset?
Who am I likely missing?
What documentation patterns could distort associations?
AI doesn’t replace domain knowledge or judgment.
It helps surface blind spots you might not see when you’re too close to the work.
A simple way to anticipate bias
Before data collection, I now map the patient journey:
- How do patients enter the system?
- What determines which data are collected?
- What influences data quality and completeness?
- Who is lost to follow-up—and why?
Then I ask: Given these constraints, what can I still claim honestly?
What comes next
Even when design, measurement, and bias are handled thoughtfully, one final stage remains. Interpretation.
This is where careful work can be undone by a few sentences—where technically correct results turn into misleading conclusions.
That is where we turn next.